At zeotap, a large amount of structured and unstructured data from data partners is transformed and converted to easily queryable, standardized data sets, which are fanned out to a variety of destinations. For this processing, the transformation jobs use Apache Spark as the distributed computing framework, with a fair share of them being batch processing jobs. Batch processing is defined as a non-continuous processing of data. A lot of the batch processing done at zeotap regularly processes files at a given frequency, with the input data being gathered in between the processing jobs.
We currently use two different types of systems to launch and manage these Spark jobs.
- Apache Oozie
- Apache Livy
An introduction to Oozie, and how we use it has been given here. In this article, we will be focussing on Livy, and how we use it at zeotap.
Oozie vs Livy
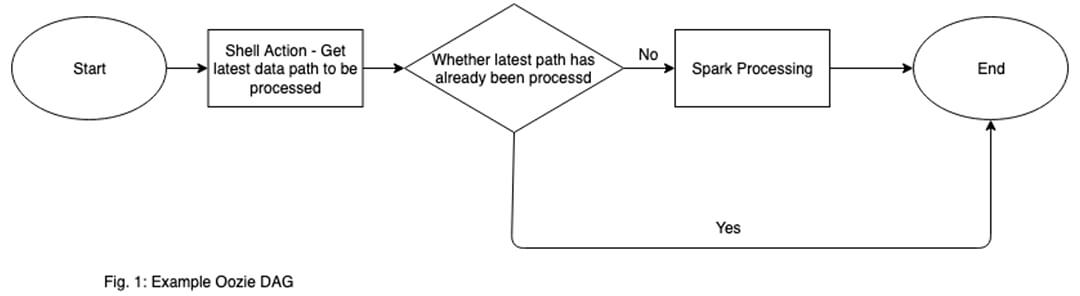
Oozie is a workflow management system, which allows for launching and scheduling various MapReduce jobs. A workflow is defined as a Directed Acyclic Graph (DAG) of actions (which can include Spark Batch Jobs), which is defined in an XML File.
Livy, on the other hand, is a REST interface with a Spark Cluster, which allows for launching, and tracking of individual Spark Jobs, by directly using snippets of Spark code or precompiled jars.

Both these systems can be used to launch and manage Spark Jobs, but go about them in very different manners. Where can we use Oozie, and where can we use Livy?
Oozie
Oozie can be used when the processing flow involves multiple steps, each of which is dependent on the previous one. This is why a DAG is required to launch Oozie Workflows. A simple example of such a dependency would be of running a script to check whether the expected input files are present or not before the actual processing takes place on those input files.
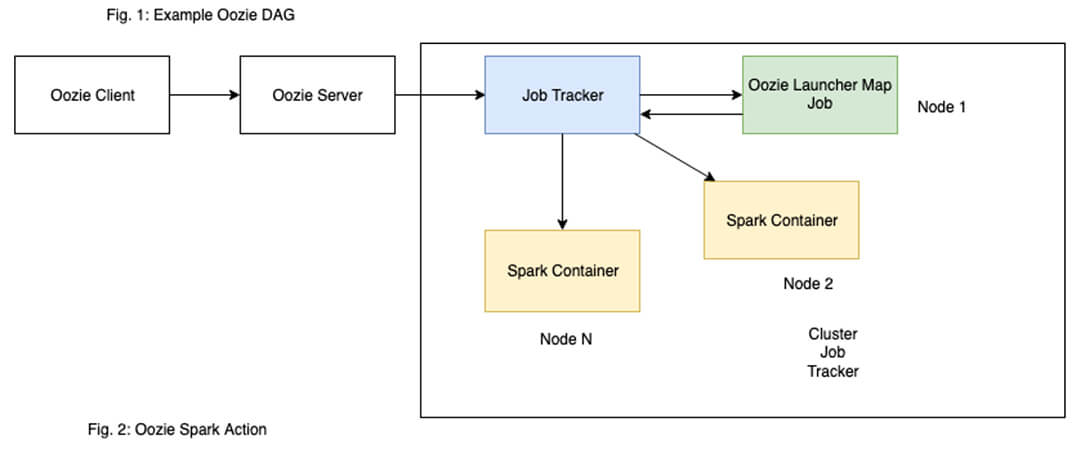
When oozie launches a spark job, it first launches an ‘oozie-launcher’ container on a core node of the cluster, which in turn launches the actual Spark Job. Oozie uses this oozie-launcher container to track and wait for Spark job processing.
Pros:
- Workflow Management – Oozie supports coordinator and workflow management. It is a more generic framework, as compared to Livy (which is just used for launching and managing Spark Jobs specifically), supporting running and scheduling of workflows.
- Versatile – Oozie supports much more than just Spark jobs, and is used for managing a wide variety of Hadoop jobs, such as Pig, Hive, Sqoop, Distcp to name a few more. This gives Oozie a large variety of use cases.
Cons:
- Cluster Choke – Oozie launches an oozie-launcher container (Fig. 2), for each job it launches. When multiple jobs are launched concurrently, there is a possibility that all the oozie-launcher are running on the cluster, but none of the Spark Jobs. Now those oozie-launcher containers are waiting for their respective Spark jobs to complete, but none of the actual Spark jobs have been launched. This means the cluster is choked with oozie-launchers.
- Jar Hell – A pro for Oozie, being its versatility in launching multiple types of Hadoop jobs, also turns out to be a reason for a con. Each type of job requires its own jars and version of libraries. This can cause library jar and classpath issues, where different incompatible versions of a library can cause failures in jobs, if not properly set up.
- The above point can also cause migration between/upgrading to newer Spark versions to become a more involved process, as jar version conflicts are bound to crop up when upgrading versions, which are often difficult to resolve.
- Workflow Maintenance – Need to write workflows to launch even the simplest of jobs. (Fig. 1)
Livy
Livy can be used to launch ‘asynchronous’ Spark Jobs which are not dependent on, and also do not have any jobs dependent on them. By ‘asynchronous’, we mean that these jobs can be launched at any time, and we do not need to wait for the response of the job.
Since jobs launched through Livy are asynchronous, they can just be launched by a parent processing workflow, and then can continue on its own without waiting for the response about this job. Such jobs would often produce results that are further also asynchronously consumed. Some such examples are:
- Data quality reporting jobs, involving stats such as row counts, column cardinality, etc. would write to a database, which is then further consumed for dashboard generation.
- Terminal jobs of a pipeline, such as jobs to prepare and export data to an external system.
But, this does not mean that Livy’s features cannot be used to Orchestrate workflows. We could possibly wait for a job’s response, by simply polling the API. Indeed using this, at zeotap, we
have leveraged Livy to launch and monitor spark jobs, and built one part of a decision making, and orchestrating framework, which supports workflow management, similar to Oozie.
Pros:
- Simple HTTP interface to launch, interact and track Spark Jobs.
- Unlikely to cause any jar issues, as it is pre-bundled with the requisite jars, and just having Spark set up correctly on the cluster is enough.
- Easy migration between Spark Versions. If the job runs on the newer Spark Version, Livy will launch it.
- Do not need to write additional workflow files, and properties to launch jobs.
- Will not choke clusters with additional tracking jobs (like ‘oozie-launcher’ – Fig. 2, 3).
Cons:
- Less versatile than Oozie for launching jobs supports only Spark jobs.
- Not a workflow management system. Purely used to launch and track single Spark Jobs. But, a workflow management system can be built around this.
Livy Features
Spark allows launching two types of data analysis options:
- Interactive: Using spark-shell and pyspark. This launch mode allows for commands to be submitted at runtime.
- Batch: Using spark-submit to launch an application on a cluster, with pre-compiled code, without any interaction at run time.
Livy supports these two modes using the REST interface as well.
Interactive / Session
In Interactive Mode (or Session mode as Livy calls it), first, a Session needs to be started, using a POST call to the Livy Server. This will start an Interactive Shell on the cluster for you, similar to if you logged into the cluster yourself and started a spark-shell.
Batch
In batch mode, the code to be executed needs to be already pre-written in a file; This could be a python file or compiled jar, which can then be stored on the cluster and used to launch the job.
Create Session:
curl -X POST \
http:///sessions \
-H ‘Cache-Control: no-cache’ \
-H ‘Content-Type: application/json’ \
-d ‘{
“driverMemory” : “1g”,
“executorMemory” : “1g”,
“numExecutors” : 2,
“name” : “livy”,
“conf” : {
“spark.test.conf” : “conf1”
}
}’
Response:
{
“id”: 0,
“appId”: null,
“owner”: null,
“proxyUser”: null,
“state”: “starting”,
“kind”: “shared”,
“appInfo”: {
“driverLogUrl”: null,
“sparkUiUrl”: null
},
“log”: [
“stdout: “,
“\nstderr: “,
“\nYARN Diagnostics: “
]
}
In both Session and Batch mode, on launching the Spark job, Livy will respond with an Integer ID which can be used for tracking the state of the Session/Batch.
Check Session State:
curl -X GET \
http:///sessions/1/state
Response:
{
“id”: 1,
“state”: “idle”
}
Setting Up Livy
Setting up Livy on a Hadoop Cluster is fairly straightforward. The prerequisites to run Livy are that the SPARK_HOME and HADOOP_CONF_DIR environment variables need to be set up on the Master Node.
If these are set, then out of the box, after extracting the Livy package to the installation folder, we can run it directly, using :
./bin/livy-server start
Configuration
By default, Livy uses configuration files present in the conf directory in the install directory. This can be changed by setting LIVY_CONF_DIR environment variables before running.
The configurations mentioned below need to be added to a file livy.conf in the configuration directory.
livy.spark.master: What spark master Livy sessions should use.
By default, it is set to local. Set it to yarn to launch using Hadoop YARN Resource Manager
livy.spark.deploy-mode : What spark deploy mode Livy sessions should use.
It is strongly recommended to use cluster deploy mode when using Livy with YARN. This ensures that the host running the Livy server doesn’t become overloaded when multiple sessions/jobs are running.
livy.server.yarn.app-lookup-timeout : How long Livy will wait and try to launch a session/job. If the cluster is busy, Livy might not be able to launch the job within this time limit. Increase this for a larger tolerance of a busy cluster.
livy.server.recovery.mode: Recovery mode of Livy. Possible values:
off: Default. Turn off recovery. Every time Livy shuts down, it stops and forgets all sessions.
recovery: Livy persists session info to the state store. When Livy restarts, it recovers previous sessions from the state store.
It is strongly recommended to set this to recovery. By default, it is in off mode. If set to off, if and whenever Livy shuts down / crashes, all sessions and jobs launched by Livy are forgotten. Furthermore, if any session is currently running, Livy will shut it down as well.
If set to recovery, ensure that the following two configs are also setup:
livy.server.recovery.state-store : Where Livy should store the state for recovery. Possible values:
: Default. State store disabled.
filesystem: Store state on a file system.
zookeeper: Store state in a Zookeeper instance.
livy.server.recovery.state-store.url: For filesystem state store, the path of the state store directory. e.g. file:///tmp/livy or hdfs:///.
For zookeeper, the address to the Zookeeper servers. e.g. host1:port1,host2:port2
At zeotap, we use filesystem state store on the local system of the master. Livy does not go down very often, and even if it does, storing the state on the local filesystem proves to be reliable enough for the use cases.
The above configurations should be enough, to allow for a stable Livy usage environment. The following configurations are required only if querying Livy and updating of the state of Spark Jobs using the API is required.
livy.server.session.state-retain.sec: How long a finished state of a session should be retained by Livy to be available for querying. By default, it is 10 minutes. Applies to both batch and sessions.
livy.server.session.timeout: This is only for sessions (and not batches launched) on Livy. This is the time on how long Livy will wait before timing out an idle session. By default, 1 hour.
Note: If you are planning to use Apache Livy on newer versions of Amazon EMR, it is already bundled, and only configurations need to be set up.
Job Tracking using Livy – Caveats
A few things to note about querying Apache Livy to track job states :
- The UI currently will show only 100 oldest jobs/sessions within the state-retain time out. The other jobs will not be visible on the UI but can be queried through the REST API.
- Livy does job tracking through integer job IDs. This could lead to mix-ups if Livy shuts down, and restarts without recovery being set, as the job IDs reset to 0 again.
- Livy logs which it returns from its APIs are usually not useful for debugging. Very limited information is available, usually just the tail end of the logs from the job. Debugging will often involve looking into the yarn application logs instead.
Apache Livy and Oozie are just two of the constituent technologies used to build the data platform at zeotap. Leveraging these two, and others, we have built a code-driven workflow management system used across multiple products here. A blog about this control plane framework will follow soon!



















